<html>
<body>
<h1>My heading</h1>
<p>Some text I wrote.</p>
</body>
</html>9 Web Scraping in R
🎯 Learning goals
After working through Tutorial 9, you’ll be able to…
- explain web scraping, including ethical and legal limitations
- explain the basics of CSS and HTML
- apply functions for web scraping
1. What is web scraping?
I understand web scraping as the automated collection and retrieval of relevant data from website code. Generally, this includes at least three steps:
Identify the URL of the website you want to scrape
Download its content
From downloaded data, separate „junk“ from relevant data
Since a lot of social media platforms have closed automated access to their data via Application Programming Interfaces (APIs), researchers increasingly have to collect data via other methods.
As a data collection method, web scraping has several advantages:
- It allows us to collect data that may otherwise not be available for research
- It allows us to collect new (meta) data (e.g., timestamps of content, multi-modal data)
- It allows us to rely on the structuredness of websites to scale-up data collection
2. Ethical, legal, and technical limitations
While web scraping has some advantages, these go hand in hand with several ethical, legal, and technical limitations. For excellent and far more detailed overviews on all of these points, see this overview article by Luscombe et al., 2022 and Brown et al., 2025. Some of these legal points need to be re-considered based on the DGPR Borg et al., 2026.
Ethically, researchers should ask: Should I scrape this website? For example, is this data public or private? Does it contain information by individuals and/or could this information be used to harm specific individuals? Do I need to circumvent blocks build by websites (e.g., logins, paywalls, etc.?) Also, by repeatedly scraping content from a website, could I involuntarily disturb the service of the website (e.g., in what may be considered a DoS attack)?
Legally, researchers should ask: Am I allowed to scrape this website? Whether and to what degree scraping is legal depends, among other contexts, on what and how much content is scraped, who is scraping this content in which country, etc. A good way of addressing both ethical and legal aspects is to follow “rules of good scraping behavior”. For example, website hosts often define which elements of their website can be scraped, by whom, and with what speed in their robots.txt, something we should respect. For the example of Wikipedia, see their robots.txt here.
Technically, researchers should ask: Can I scrape this website? Not all elements of websites could/should be accessed via scraping. For example, dynamic content is harder to scrape; the same accounts for content behind paywalls or user logins. Also, a lot of websites have made it harder to scrape their website due to the increase of Large Language Models (LLMs) scraping the web.
3. Source code
To understand web scraping, you have to understand what it relies on: source code.
Generally, websites are text documents that are interpreted and designed based on their source code. Let’s take the Wikipedia page on “Communication studies” as an example.
This is how the website looks like in my browser:
Image: Wikipedia page
Now, let us look at the underlying code (click on the right, then choose “View Page Source” or “View Source” depending on your computer). For different options to do so across browsers and operating systems, see here.
Image: Wikipedia page Source Code
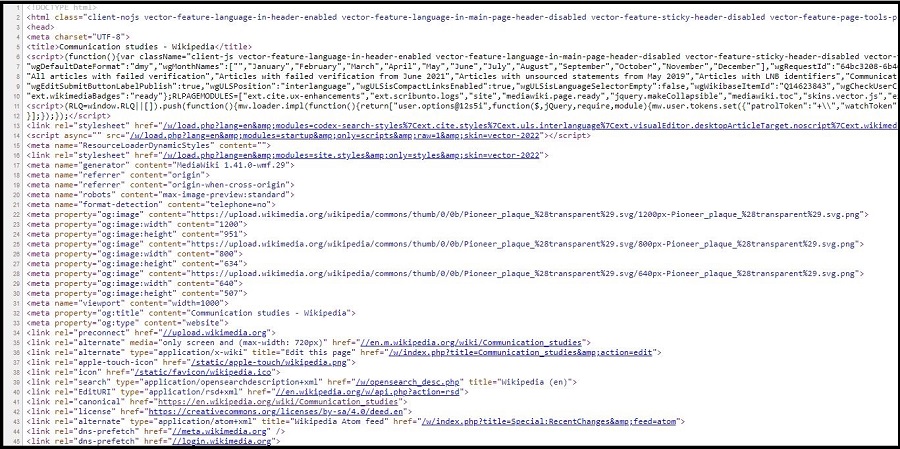
You can see: Websites are simple text documents (ok, the code does not look simple - but we can easily understand parts of it!). When you visit websites, your browser reads the underlying source code (e.g., HTML, CSS, Javascript) to correctly display the website.
- HTML (Hypertext Markup Language): is a “markup language” that defines the structure of websites. “Markup” means that the code includes additional info besides just the content you want to display. For example, you can use HTML to define the title of your website: you may not only include information on the content of the title, but also where and how it should be displayed.
- CSS (Cascading Style Sheets): is a “style sheet” language we use to change the design of websites. For example, you can use CSS to define the color of the title of your website.
- JavaScript: is a language we also use to change the design/behavior of websites (mostly for dynamic and interactive elements). For example, you can use Javascript to automatically play a video when you hover over the title of your website.
In the following, we will focus on understanding the basics of HTML and CSS to learn web scraping.
3.1 HTML
You can use HTML (Hypertext Markup Language) to structure websites. For our seminar, you mainly need to know three things about HTML:
Websites consist of nested elements. For example, this is an element:
<body>Some content</body>. This gives HTML files a “tree-like” structure where elements are nested in elements nested in elements etc. For example, the element<body>Some content</body>is usually nested inhtml:<html><body>Some content</body></html>Most elements (e.g.,
<body>Some content</body>) consist of a tag which marks the beginning<>of an element. Similarly, a tag marks the end of the element</>(this differs for some elements, but we can ignore this for now). In between these tags is some content, e.g. text. For example: the element<h1>My heading</h1>consists of a start tag (<h1>), content (“My heading”), and an end tag (</h1>). What type of tag is used tells us a bit about what content we may expect (e.g., inh1we may expect a title, inimgan image - which is useful information for automatically scraping such code!).You can also include attributes in-between tags. Attributes provide additional information. For example, we may want to add a link to our heading “My heading” from above. We could do that via the
atag (an “anchor” tag used to embed links) and an additionalhrefattribute that specifies where the link should guide readers.
A typical HTML text may look like this:
What does this mean?
- the
<html>element is the root element of an HTML website - the
<body>element defines the document’s body (where text, images etc. are included) - the
<h1>element defines a large heading - the
<p>element defines a paragraph
On a website, the HTML snippet above is rendered to only the following two sentences:
Output of HTML snippet
My heading
Some text I wrote.
If you want to try this yourself, copy-in the HTML code here and try to play around with it a bit.
As you can see, while the HTML file contains a lot of information, only some of it is displayed here. Most of it is, instead, used to structure text “in the background”.
Next, let’s try to include a link for the text “Some text I wrote”. We can use the a anchor and the href attribute (including the link, here to Google).
<html>
<body>
<h1>My heading</h1>
<p><a href="https://www.google.de/">Some text I wrote</a></p>
</body>
</html>On a website, the result looks like this (try clicking the link!):
Output of HTML snippet
My heading
You may ask yourself: Great - so why exactly should you know about HTML?
Knowing about the structure of HTML files (and what type of content different elements contain) is important to systematically parse relevant data from websites.
For example, articles in news websites will often be included in body, article titles in h1, etc. So we could look for these tags/elements when scraping news websites to only extract the title and text of a news article.
3.2 CSS
While you could fine-tune the appearance of your website via HTML elements (e.g., <b>, <i>), developers came up with CSS (Cascading Style Sheets) to more neatly format the appearance of HTML pages.
For our seminar, you mainly need to know four things about CSS:
Rules are the building blocks of CSS. They describe how different sections of websites should be formatted. Rules consist of selectors and declaration blocks. For example, a rule could define that all headings of a website should be displayed in the color red.
Selectors define which HTML element you want to style. In the example above, the selector could be the element
h1, which stands for the first heading.Declaration blocks describe how the element should be styled by including information on properties (e.g., please set my
color) and values (e.g., please set it tored).There are different ways in which we can include CSS in HTML. Here, we will discuss inline CSS (defining rules for every single element) and internal CSS (defining rules for types of elements, so-called classes).
3.2.1 Inline CSS
Let’s try to change the color of my h1 heading “My heading”. My new rule should be that all headings h1 should displayed in red.
How do I do this?
- I want to change the content included in the heading
h1element via inline CSS. To do so, I change thestyleattribute within theh1element. - I want to change the color of this element, so I include the property
colorwithin thestyleattribute. - I want to change the color of this element to red, so I include the value
redfor the propertycolorwithin thestyleattribute.
<html>
<body>
<h1 style="color:red;">My heading</h1>
<p>Some text I wrote</p>
</body>
</html>On a website, this changes the color of the h1 element:
Output of HTML snippet
My heading
Some text I wrote
3.2.2 Internal CSS
The inline version above is a bit inefficient, since you would have to include information on the color for every single heading (making your code very long and more prone to errors).
Instead of inline code, we could also use internal CSS: Here, we define rules not for every single element (e.g., every h1) but for types of elements, so-called classes. We define a CSS style for all elements of a certain class and assign this class to elements we want to be displayed in a certain way via attributes.
Let’s say, for example, that we only want parts of “Some text I wrote” to be depicted in pink:
- I create a new
class.text-pinkfor text that should be pink within the<style>element. Notice how<style>is now defined at the beginning of the document, so not related to a specific element.
- For
.text-pink, I want to define a color, so I include the propertycolor. - For
.text-pink, I want to set the color topink, so I include the valuepinkfor the propertycolor. - To mark which words of “Some text I wrote” should be depicted in pink, I can use the
<span>element.<span>is used to mark specific parts of text. I only want the word “text” to be pink, so I include “text” between<span>and</span>.
<html>
<style>
.text-pink {
color:pink;
}
</style>
<body>
<h1 class="heading-new">My heading</h1>
<p>Some <span class="text-pink">text</span> I wrote</p>
</body>
</html>On a website, this changes the color of the word “text”:
Output of HTML snippet
My heading
Some text I wrote
Again, you may ask yourself: Great - so why exactly should you know about CSS?
Again, knowing about the structure of CSS syntax is important to systematically parse relevant data from websites.
For example, articles in news websites may be formatted according to a specific style, e.g., the class style-article. We could look for style-article when scraping news websites to only extract the text of the article (and ignore all “junk code” around it).
4. Let’s go: Web scraping in R
Let’s try this. Remember the steps of scraping you learned about in the last tutorial:
Identify the URL of the website you want to scrape
Download its content
From downloaded data, separate „junk“ from relevant data
4.1 Identify URL of website
Let’s again take the Wikipedia page on “Communication studies” as an example: https://en.wikipedia.org/wiki/Communication_studies
This is how the website looks like in my browser:
Image: Wikipedia page
Now, look at the underlying code (click on the right, then choose “View Page Source” or “View Source” depending on your computer/browser).
Image: Wikipedia page Source Code
To be sure that we can scrape the website, take a look at Wikipedia’s “robots.txt” file here.
4.2 Download website content
To download the source code, we download and activate two packages:
While rvest allows us to scrape and parse content, polite assures that we adhere to “good behavior” while doing so. With polite, we can…
- tell website owners who we are
- respect which website content we are (not) allowed to scrape
- time our scraper so that we do not constantly hit websites with our scraping requests
install.packages("rvest")
install.packages("polite")
library("rvest")
library("polite")Next, we use the bow() command polite to “introduce” us to the website and see whether we can scrape it:
session <- bow(url = "https://en.wikipedia.org/wiki/Communication_studies",
user_agent = "Teaching project,
Valerie Hase,
Department of Media and Communications,
AAU Klagenfurt")
#Result
session<polite session> https://en.wikipedia.org/wiki/Communication_studies
User-agent: Teaching project,
Valerie Hase,
Department of Media and Communications,
AAU Klagenfurt
robots.txt: 464 rules are defined for 34 bots
Crawl delay: 5 sec
The path is scrapable for this user-agentWhen inspecting the result, we can see that we are allowed to scrape this website. However, we should wait for 5 seconds in-between scraping requests.
We now use the scrape() command to implement these rules while scraping the website:
url <- scrape(session)Important: If the url object is empty (i.e. NULL), it may be that you are not allowed/cannot scrape this website.
4.3 Identify relevant HTML elements
Remember the third part of scraping: separating „junk“ from relevant data. Now this is actually the hardest part. From the long HTML code, how do we find (and keep) relevant data?
The solution: We have to identify the right selector (e.g., an element, a class, an attribute) and retrieve it via html_element (retrieves the first match) or html_elements (retrieves all matches).
The following Table gives you a small overview of common commands for retrieving selectors based on this great, more detailed overview by T. Gessler. The W3 school also has a great overview here.
| Command | Example | Meaning |
|---|---|---|
html_elements(element) |
html_elements(p) |
retrieves all elements p |
html_elements(element, element) |
html_elements(div, p) |
retrieves all elements div and p |
html_elements(element element) |
html_elements(div p) |
retrieves all elements p inside div |
html_elements(.class) |
html_elements(.article) |
retrieves all elements with class article |
html_elements(element.class) |
html_elements(p.article) |
retrieves all p elements with class article |
html_elements(element) |> html_attr(attribute) |
html_elements(a) |> html_attr(href) |
retrieves all links within elements a |
html_elements(element) |> html_attr(attribute) |
html_elements(img) |> html_attr(src) |
retrieves the source of all images within elements img |
To find the right selector, you can…
- Inspect: click right on the specific element and choose “Inspect”, which will open the underlying source code
- SelectorGadget: use SelectorGadget to automatically find the right selectors. To install SelectorGadget, click on this link. Install the Chrome Extension (link at the end of the website, search for “Try our new Chrome Extension”). For a more detailed instruction of how the tool works, see here.
4.3.1. Example 1: Scrape a website title
For example, let’s say I want to extract the title of the website. Using the Inspect function (right click, then inspect to open the source code), we can see that Wikipedia has defined its own class for the title: .mw-page-title-main.
Image: Wikipedia page Source Code
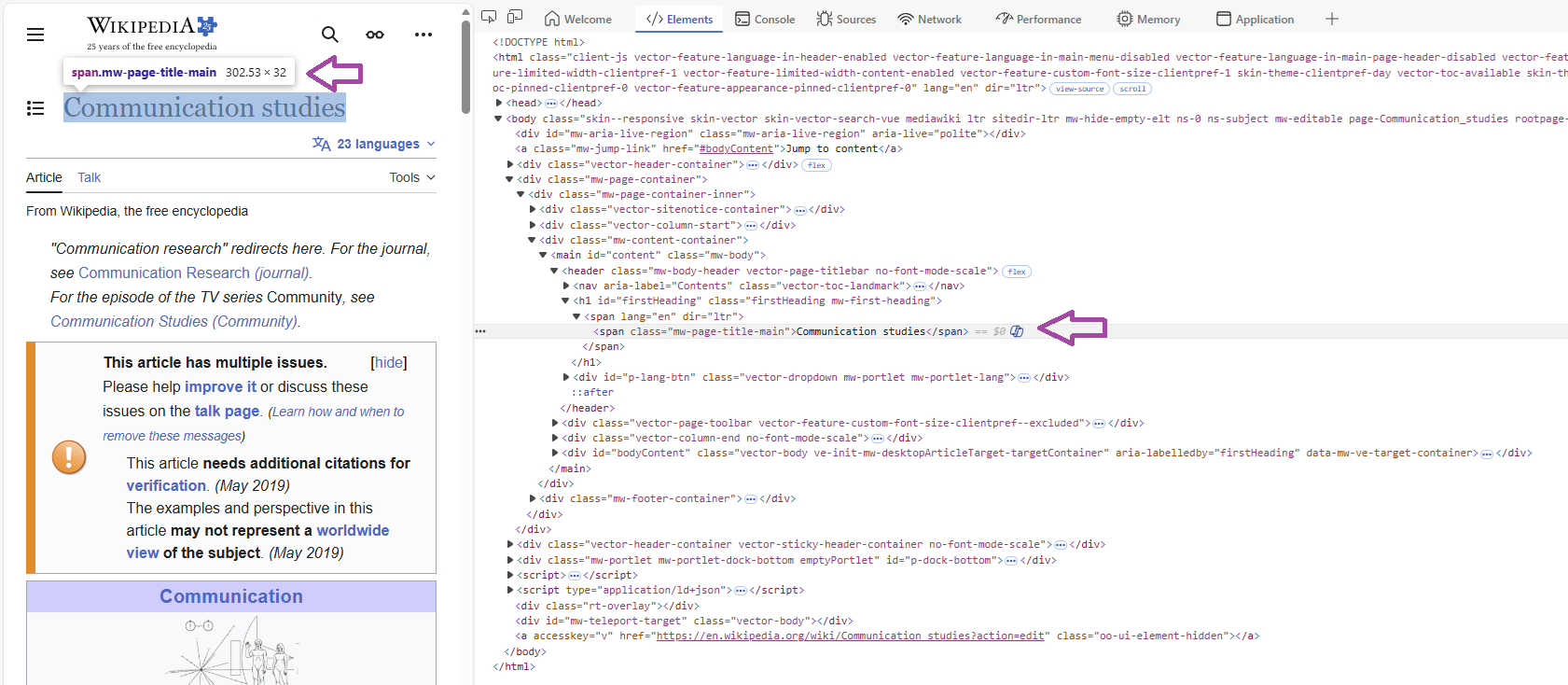
Using the html_elements function from rvest, we now only keep relevant content:
url |>
html_elements(".mw-page-title-main"){xml_nodeset (2)}
[1] <span class="mw-page-title-main">Communication studies</span>
[2] <span class="mw-page-title-main">Communication studies</span>Great, but we only want the content within span, not all “junk” around it.
To clean our data, we can now use the html_text() command:
url |>
html_elements(".mw-page-title-main") |>
html_text()[1] "Communication studies" "Communication studies"4.3.2. Example 2: Scrape website subheadings
Let’s try another example: Let’s say we want to extract all subheadings.
We already know that subheadings are often indicated by h1, h2, etc., so we use this information to retrieve all headings from h1 to h6. We can combine selectors like so:
url |>
html_elements("h1, h2, h3, h4, h5, h6") |>
html_text() [1] "Contents"
[2] "Communication studies"
[3] "History"
[4] "Origins"
[5] "Foundations of the academic discipline"
[6] "In the United States"
[7] "In Canada"
[8] "Scope and topics"
[9] "Business"
[10] "Healthcare"
[11] "Professional associations"
[12] "See also"
[13] "References"
[14] "Bibliography" 4.3.3. Example 3: Scrape website text
Let’s try another example: Let’s say we want to scrape the text of the article. For this, we retrieve all paragrahs as indicated by p.
url |>
html_elements("p") |>
html_text() |>
#we only want to read the first block of text
head(1)[1] "Communication studies (or communication science) is an academic discipline that deals with processes of human communication and behavior, patterns of communication in interpersonal relationships, social interactions and communication in different cultures.[1]Communication is commonly defined as giving, receiving or exchanging ideas, information, signals or messages through appropriate media, enabling individuals or groups to persuade, to seek information, to give information or to express emotions effectively.[2][3] Communication studies is a social science that uses various methods of empirical investigation and critical analysis to develop a body of knowledge that encompasses a range of topics, from face-to-face conversation at a level of individual agency and interaction to social and cultural communication systems at a macro level.[4][5]"If you look at the output, you see that this worked (although the text is a bit messy and probably needs some more cleaning).
4.3.4. Example 4: Scrape website links
One last example: Let’s say we want to extract all links included in the main text (something also discussed in the context of “crawling”, i.e., identifying links to follow on websites to identify further content).
- We know that these links are inside the main text within the element(s)
p - We know that links are usually included within the element
a - We know that links are saved as attributes
hrefwithina
Combining the html_elements() and the html_attr() commands, we can now get all links:
url |>
html_elements("p") |>
html_elements("a") |>
html_attr("href") |>
head()[1] "/wiki/Academic_discipline" "/wiki/Human_communication"
[3] "/wiki/Human_behavior" "/wiki/Interpersonal_relationship"
[5] "/wiki/Social_interaction" "/wiki/Culture" These are all links to other Wikipedia pages (i.e., internal links), which is why they do not start with “https” etc.
🤓 Smart Hacks
Smart Hack: Automated the scraping process
Oftentimes, you may want to automate your scraping process, for example by writing a timer that automatically runs your scraping script every x-th minute.
To automate the scraping process, packages like taskscheduleR offer great a solution.
install.packages("taskscheduleR")
library("taskscheduleR")Using taskscheduler_create(), you can tell your computer to run a scraping script automatically at a dedicated time. Just define the task name via taskname and tell R which script to run via rscript. Next, well R that you want to run the script every 5 minutes via schedule and modifier.
taskscheduler_create(taskname = "Automated-Scraping",
rscript = "Scraping-Skript.R",
schedule = "MINUTE",
modifier = 5)
Smart Hack: Take screenshots
For example, you may need PDF screenshots of webpages to understand what content was shown how where. To automate this process, you can use the pagedown package.
install.packages("pagedown")
library("pagedown")Using chrome_print(), you can take screenshots. Just define the URL via input and the file name for the resulting screenshot via output
chrome_print(input = "https://www.bbc.com",
output = "screenshot.pdf")Important: Usually, these screenshots are not perfect. You often have to include some “waiting” time via the wait argument so the website can fully load before you take a screenshot. Some hosts also use automated means of disallowing automated screenshots.
💡 Take-Aways
HTML: a “markup language” that defines the structure of websites
- consists of nested elements (e.g.,
body,title) marked by tags (<>,</>) (for overview lists of elements, see here) - elements may include attributes including additional information (e.g., a link via
href) (for overview lists of attributes, see here)
As an overview, see the most important types of elements and attributes in HTML (for a full list, see here):
| Element | Meaning |
|---|---|
<head> |
structure - defines meta data of a document |
<title> |
structure - defines the title of a document |
<body> |
structure - defines the document’s body |
<h1> |
structure - defines headings (h1, h2, hc, etc.) |
<p> |
structure - defines a paragraph |
<a> |
structure - defines a link |
<img> |
structure - defines an image |
<div> |
structure - defines a container in which elements can be styled via CSS/JavaScript |
<b> |
formatting - makes text bold |
<i> |
formatting - makes text italic |
CSS: a “style sheet” language that defines the design of websites
consists of rules (e.g., this element should be green) specified by selectors and related declaration blocks
rules can be specified for classes of elements
selectors describe which element should be formatted (e.g., the heading
h1)declaration blocks define what property of the selector should be formatted (e.g., its color
color) and what value should be used (e.g., `red``)
R Code for scraping:
introduce your scraping agent:
bow()scrape website:
scrape()parse content:
hmtl_elements(),hmtl_attr(),hmtl_text()screenshots:
chrome_print()automate script execution:
taskscheduler_create()
🎲 Quiz
📚 More tutorials on this
You still have questions? The following tutorials & papers can help you with that:
- HTML Tutorial by W3 School as well as CSS Tutorial by W3 School
- Webscraping and the Text Analysis Pipeline by T. Gessler
- Algorithmic thinking in the public interest by Luscombe et al., 2022) 2022.
- Web scraping for research: Legal, ethical, institutional, and scientific considerations by Brown et al., 2026
- Automated Data Collection with R: A Practical Guide to Web Scraping and Text Mining by S. Munzert, C. Rubba, P. Meißner, & D.Nyhuis
📌 Test your knowledge
Task 1 (Easy🔥)
Use your knowledge about web scraping to scrape content from the Wikipedia page on web scraping. Retrieve the main topics discussed here (see blue circled headings).
Image: Wikipedia page: Web Scraping
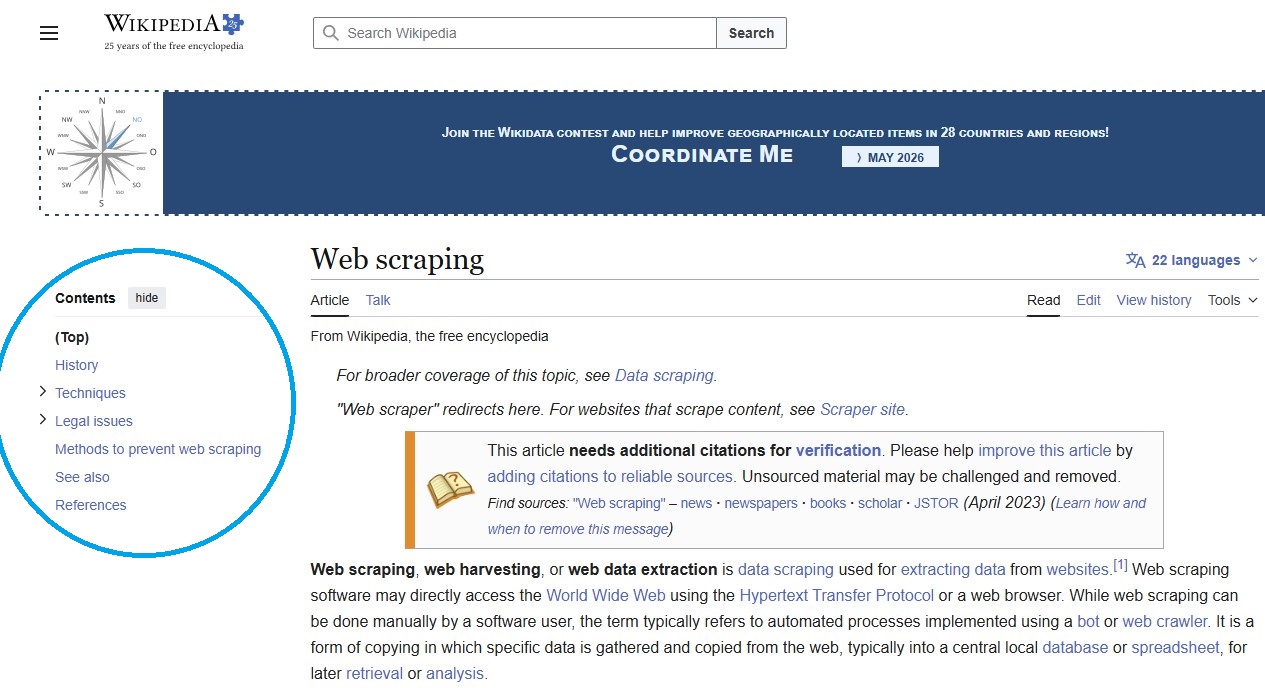
Solution:
session <- bow(url = "https://en.wikipedia.org/wiki/Web_scraping",
user_agent = "Teaching project,
Valerie Hase,
Department of Media and Communications,
AAU Klagenfurt")
# Check: Can I scrape here?
session<polite session> https://en.wikipedia.org/wiki/Web_scraping
User-agent: Teaching project,
Valerie Hase,
Department of Media and Communications,
AAU Klagenfurt
robots.txt: 464 rules are defined for 34 bots
Crawl delay: 5 sec
The path is scrapable for this user-agent# Scrape the irl
url <- scrape(session)
# Identify main topics
url |>
html_elements("h2") |>
html_text()[1] "Contents" "History"
[3] "Techniques" "Legal issues"
[5] "Methods to prevent web scraping" "See also"
[7] "References" Task 2 (Medium🔥🔥)
Now get the number of references mentioned in the reference list of this Wikipedia article. At the moment, it is 37 but this may change one you scrape the website.
Solution:
# Solution
url |>
html_elements("ol.references li") |>
html_text() |>
length()[1] 37Task 3 (Hard🔥🔥🔥)
Now, we want to collect information on the most heated Wikipedia debates!
Write a function that goes to a Wikipedia “Talk” page for a given topic (e.g., debates on the Wikipedia Web Scraping page here).
Image: Wikipedia page: Web Scraping - Talks
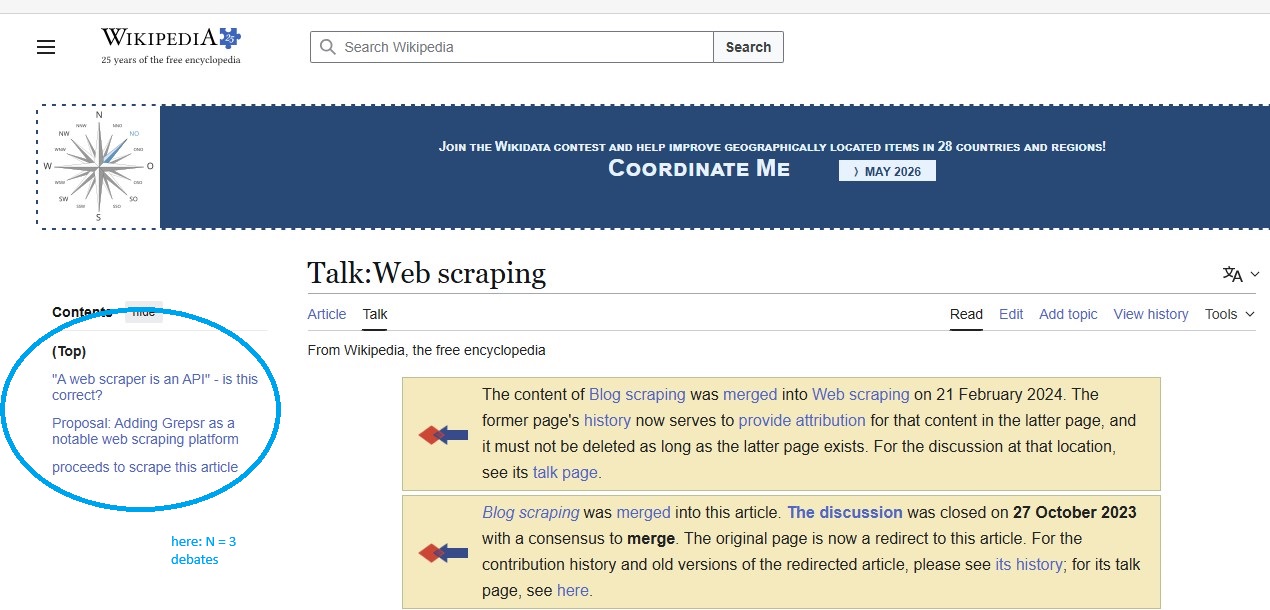
The function should ….
- Count how many discussion any Wikipedia talk page currently has.
- Save the result (topic, link, number of discussion sections).
The function should be flexible: It should run for any list of pages you give to it.
Using this function, run the function for three Wikipedia articles: Web scraping, Artificial intelligence, Algorithm. The result could/should look something like this (here, I named my function as scrape_discussion().
Solution:
library(rvest)
library(polite)
library(dplyr)
# Write a function that scrapes each Wikipedia URL
# and also counts the number of words in each discussion section
scrape_discussion <- function(page) {
# Build the unique URL
url <- paste0("https://en.wikipedia.org/wiki/Talk:", gsub(" ", "_", page))
# Build the unique user agent
user_agent <- "Teaching project, Valerie Hase, Department of Media and Communications, AAU Klagenfurt"
# Introduce your scraping agent
session <- bow(url, user_agent)
url_scraped <- scrape(session)
# Extract all text from the Talk page body
discussion <- url_scraped |>
html_elements("h2") |>
# substract one, since "Content" heading is not a discussion point
length() -1
return(tibble(
article = page,
url = url,
discussion = discussion
))
}
# Run and compare two articles
results <- bind_rows(
scrape_discussion("Web scraping"),
scrape_discussion("Artificial intelligence"),
scrape_discussion("Algorithm")
)
results# A tibble: 3 × 3
article url discussion
<chr> <chr> <dbl>
1 Web scraping https://en.wikipedia.org/wiki/Talk:Web_scr… 1
2 Artificial intelligence https://en.wikipedia.org/wiki/Talk:Artific… 5
3 Algorithm https://en.wikipedia.org/wiki/Talk:Algorit… 5# Run and compare number of discussions on articles
bind_rows(scrape_discussion("Web scraping"),
scrape_discussion("Artificial intelligence"),
scrape_discussion("Algorithm"))# A tibble: 3 × 3
article url discussion
<chr> <chr> <dbl>
1 Web scraping https://en.wikipedia.org/wiki/Talk:Web_scr… 1
2 Artificial intelligence https://en.wikipedia.org/wiki/Talk:Artific… 5
3 Algorithm https://en.wikipedia.org/wiki/Talk:Algorit… 5